
CPU Experiment
April 2, 2017
This article aims to leave some practical notes for juniors who will experiment the CPU Experiment next year.
What is the CPU Experiment?
In the Department of Information Science at the University of Tokyo, bachelor 3rd students have to create their CPU and compiler as an assignment. The goal of the class is to run a lay-tracing program with their architecture as fast as possible. Following sections describe what I wish I knew when the experiment started. I hope your good luck.
Index
- before you start
- beginning the experiment
- what helps you to avoid some bugs
- additional comments
- additional links
Some referrences
books
These books are also useful in other courses.
- コンピュータ設計の基礎
- 高性能コンピュータ技術の基礎 (highly recommended)
- Computer Architecture, Fifth Edition: A Quantitative Approach
- FPGAプログラミング大全
- RTL設計ガイド
specs and user guides
Links may be old. Search by your own with guide number. User guides and product guides are those of Xilinx. If a provider change, then search those of the new provider. Especially, be careful that different providers support different subsets of functionality in HDL.
- SystemVerilog IEEE spec
- AXI spec
- UG893 vivado ide
- UG901 systhesis
- UG1037 AXI
- UG896 IP
- PG058 block memory generator
- PG060 floating point
- UG903 constraints
- UG628 command line tools
Role sharing
In the CPU Experiment, each team is composed of about four members (this may change next year). Each team must have members who are in charge of core architecture and who of a compiler. Who takes charge of them are chosen by candidacy system first, and next, team members are decided at random. What role other two members handle are arbitral. Each team can decide their position. It was common that the other two members are in charge of a simulator and a library.
Even though assigning a member to be in charge of a simulator is common in many years, I thought this doesn’t work well. There are mainly two points.
- Misunderstanding of specification between core and simulator makes debugging harder.
- A member in charge of the simulator can often be a bottleneck in debugging of the core.
Though these two did not occur in my team, it seemed common in many other teams. As a result, it is not rare that a member in charge of core creates his simulator. Based on those, I think that it’s better to make the core responsible for a simulator and creates another position instead of the simulator. Some candidates for that are described in the next section.
Scheduling
In this section, I’ll describe three points to keep in your mind when you develop the development schedule.
First of all, you should make a minimal architecture that satisfies project requirements first. Though it may seem too easy for you, it is beneficial.
Second, use much time for comprehending specifications of FPGA, HDL(SystemVerilog), IP cores, and so on. Though it is tedious and takes a long period, making full use of them is quite important to improve the efficiency of your jobs. A month of learning is worth years of blind works. Do not rush to complete your CPU, I recommend. Even creating a position who finds out the usage of tools and looks through specifications is a good choice, I think.
Third, testing takes much time than you think. Simulation with the simulator embedded in IDE is slow. Making good test cases also takes time. On combined test, it’s hard to detect where and when the bug came to light. Assigning members a job to help to make test cases and doing simulation will be much help.
Tips
- if you leave the power of FPGA turned on for a long time, it will go wrong
- when serial communication fails, the USB cable may have some problems, especially when some tools like ‘cutecom’ seem wrong
- when you write serial communicator by your hand, it is known that lowering the cycle from theoretical value may help (in my experience, it worked well when reduced by around five percents)
- though it is confusing how to make clock on the FPGA board of CPU Experiment, you can easily get the clock using clocking wizard IP
- if you set the clock frequency too high in IDE’s simulator, it will cause problems. keeping frequency around 100-300MHz will work well.
- syntax error may not be detected by IDE and comes on light with simulator’s segmentation fault or different behavior between simulator and FPGA board
- using wire before it’s declaration may cause different behavior between simulator and FPGA board
- making use of SystemVerilog’s functionality like struct and package will help
- floating point IP core’s precision like ‘fused multiply add’ may cause problem so read specifications well
- keeping log in both your HDL code and simulator’s code, and taking diff of them is useful to reduce time needed to detect when and where bugs occur
- changing target program slightly, or changing algorithm of branch predictor can make hard bags easier to identify
Some causes of bugs I and some of my friends encountered
- implementation of branching (this is error prone, and I recommend you to transplant your SystemVerilog implementation to simulator written in more high-level language to check the logic)
- implementation of sign extension (this is also error prone)
- turning on valid flag after looking ready flag in AXI protocol, which is forbidden
- undefined behavior caused by collision at block RAM (read specs)
- index out of range at memory (this should be checked with some functionalities like ‘assert’)
- uninitialized frame pointer and stack pointer
- a queue which stocks data received through USB did not work well and information were overwritten in some conditions
- difference of endian between assembler and program loader
- unstabilized signals with switches and buttons
Additional comments
In designing CPU, it is crucial to detect bottleneck and improve where the bottleneck is. Though I created a CPU with functionality like out-of-order, superscalar, speculative execution e.t.c., not all of them much contributed to speed up despite the hardness of their implementation. Primarily, I felt that the superscalar, which was most difficult to implement, did not contribute well to increasing speed. Before you try to make a complex CPU, think again and again whether it improves speed and search any other cheaper methods which can alter the complex one.
In the implementation of CPU, unifying the way of communication between modules will help. I’ll show you a basic pattern I used for that purpose. It passes data only when both a valid flag and a ready flag is high. Of course, you don’t have to follow this but I recommend you to think your own way.
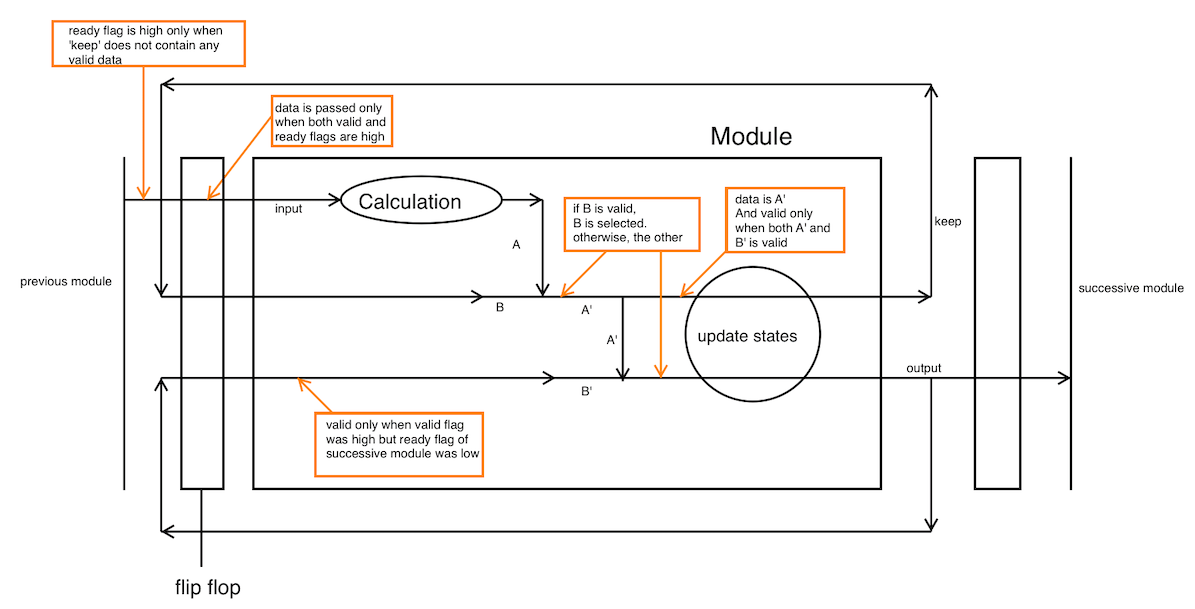
A queue was a component I used repeatedly. I adopted an implementation which does not move elements but only the pointers, like ‘commit ring’, for all of them. I found it makes it easier to follow the waveform on the IDE’s simulator. (Though I planned to put a digram of it, I won’t because of my laziness.)
Design overview of my CPU was like that of Nehalem (diagram) (though mine is unicore and much simpler). You can see a simpler diagram in 高性能コンピュータ技術の基礎’s Section5.
{kind=link}